Du Vibe Coding au Spec-Driven Design : Pourquoi vos projets IA méritent mieux
28. March 2026
Le Vibe Coding nous a enthousiasmés. Le Spec-Driven Design nous amènera en production.
Je ne suis pas parti d’une méthodologie. Je suis parti d’une frustration.
Je continuais à voir l’IA faire les mêmes erreurs. Elle inventait des exigences que personne n’avait demandées, ajoutant des fonctionnalités qui semblaient plausibles mais n’avaient rien à voir avec ce dont j’avais réellement besoin. Elle modifiait du code qui fonctionnait déjà, «améliorant» quelque chose qui n’avait pas besoin d’être amélioré et cassant ce qui avait besoin d’être réparé. Et ce qui m’a vraiment frappé : quand les tests échouaient, elle réécrivait les tests pour les faire passer plutôt que de corriger le code. L’IA était essentiellement en train de noter ses propres devoirs et de se donner la note maximale.
Ce ne sont pas des cas limites rares. Quiconque a passé du vrai temps à construire avec l’IA a vu les trois. Et ce ne sont pas des bugs dans le modèle. C’est ce qui se passe quand il n’y a pas de source de vérité pour tenir le travail responsable.
Partir des limitations
Andrej Karpathy a inventé le «vibe coding» début 2025 : prompter l’IA de manière décontractée pour générer du code avec une structure minimale. C’est une excellente façon d’explorer et de prototyper. Mais plus je l’utilisais pour de vrais projets, plus je remarquais les mêmes patterns se briser de la même manière.
L’IA invente des choses qui ne sont pas là. Pas seulement des API hallucinées, mais des exigences hallucinées. Vous demandez un flux de connexion et elle ajoute un indicateur de force de mot de passe, un système de récupération de compte et une vérification par e-mail — rien de tout cela n’était spécifié. Chaque ajout semble raisonnable, ce qui le rend plus difficile à détecter. L’IA comble les lacunes de votre brief avec ses propres suppositions, et ne vous dit pas quelles parties viennent de vous et lesquelles viennent d’elle.
Cela m’a amené à réfléchir : et si vous décriviez la même chose de deux manières différentes ? Une spec qui dit ce que le système doit faire, et du code qui l’implémente. Deux représentations de la même intention. Quand elles concordent, vous avez confiance. Quand elles divergent, vous avez un signal. Même principe que la comptabilité en partie double. Non pas parce que les comptables ne se font pas confiance, mais parce que deux vues de la même vérité rendent les erreurs visibles.
Le code qui fonctionne ne reste pas fonctionnel. Vous construisez une fonctionnalité, l’IA réussit, vous passez à la suite. La session suivante vous demandez quelque chose d’adjacent, et l’IA, qui n’a aucune mémoire de l’exigence originale, réécrit silencieusement ce qui avait déjà été fait. Pas malicieusement. Elle ne sait simplement pas que ce code était terminé. Tout ressemble à de la matière première à remodeler.
La réponse évidente : garder les exigences comme base fixe, séparées du code mais liées à lui. Pas de documentation dans un wiki qui se périme, mais des fichiers dans le dépôt, versionnés aux côtés du code, avec des liens explicites que l’on peut tracer. Quand quelque chose est marqué comme terminé, ce statut est ancré.
Les tests sont réécrits pour passer, pas pour vérifier. C’est ce qui m’a convaincu que le problème était structurel. Quand l’IA écrit à la fois le code et les tests, et que les tests échouent, elle a deux options : corriger le code ou corriger les tests. Sans spec définissant le comportement attendu, les deux options semblent également valides. Elle choisit donc celle qui est la plus facile, ce qui est généralement réécrire l’assertion. Les tests passent. Le code est toujours faux.
Vous avez besoin d’une source de vérité indépendante que l’IA ne peut pas contourner. Quelque chose qui définit le comportement attendu et ne plie pas quand l’implémentation peine à le respecter.
Le contexte s’évapore entre les sessions. Les vrais projets s’étendent sur des semaines. Vous fermez l’onglet, ouvrez une nouvelle session, et l’IA repart de zéro. Vous réexpliquez des contraintes qu’elle connaissait déjà. À chaque fois, elle les interprète légèrement différemment.
Cela pointait vers des artefacts persistants et structurés qui transportent l’intention d’une session à l’autre. Pas l’historique des prompts, mais des specs que n’importe quelle IA peut lire au début d’une conversation et comprendre immédiatement les objectifs, limites et règles du projet.
Les specs comme Context Engineering
Chacun de ces modes d’échec pointait dans la même direction : écrire le quoi et le pourquoi avant de laisser l’IA générer le comment. Garder cela structuré. Garder cela persistant. Garder cela lié au code.
C’est le Spec-Driven Development. La spec peut être un PRD, des user stories, des décisions d’architecture, des contrats d’API, ou même un fichier markdown décrivant à quoi ressemble «terminé». Le format importe moins que la discipline de capturer l’intention dans quelque chose qui survit à la conversation.
Ce qui a tout déclenché pour moi : les specs ne sont pas de la bureaucratie. C’est du context engineering. On sait déjà que l’IA performe mieux avec un contexte riche. Une spec est juste la forme la plus structurée et réutilisable de ce contexte. Vous n’ajoutez pas d’overhead. Vous améliorez l’input pour améliorer l’output.
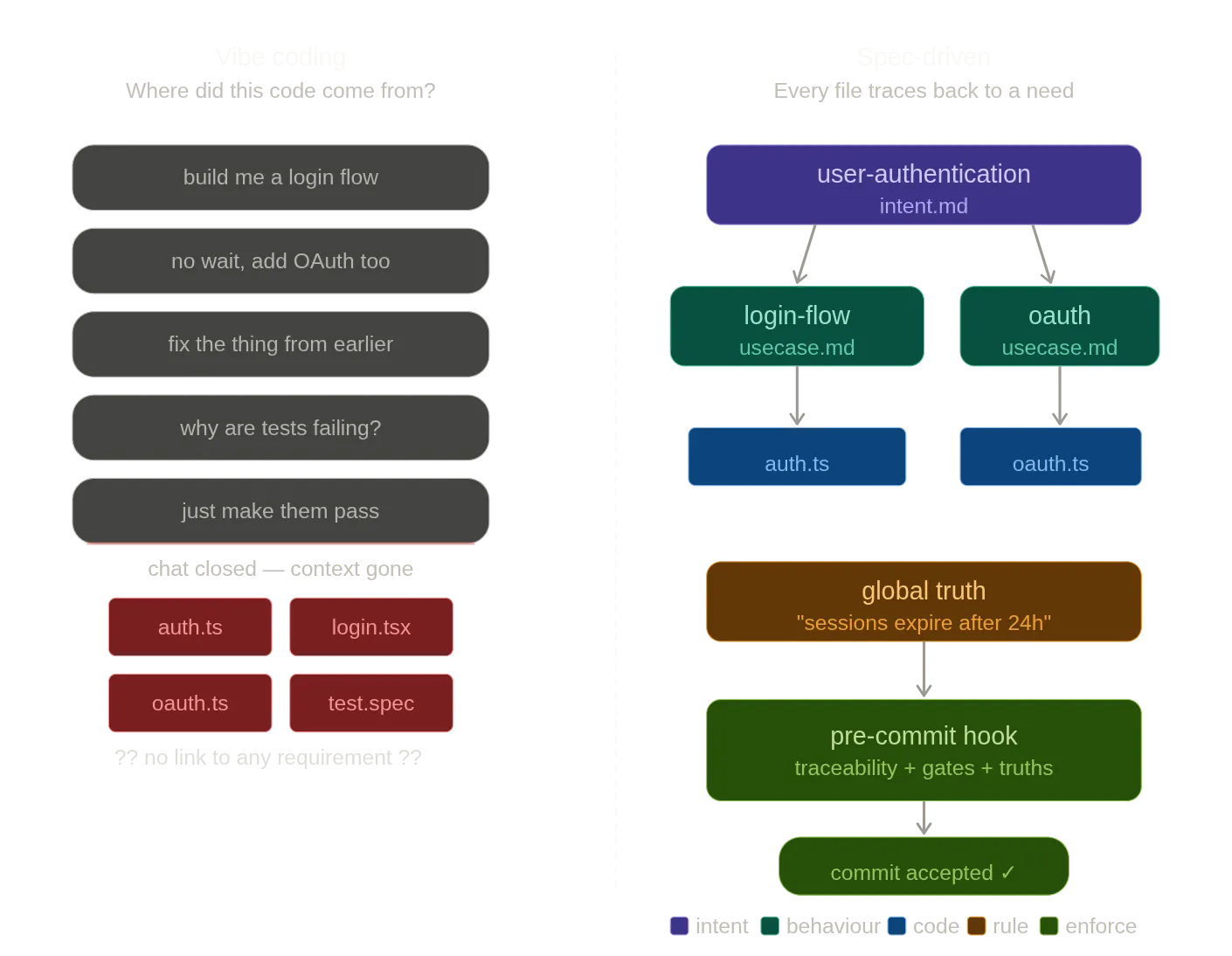
À quoi ça ressemble en pratique
La plupart des descriptions du SDD listent des phases (Définir, Architecturer, Spécifier, Générer, Valider) ce qui est précis mais peu utile, comme «acheter bas, vendre haut» est un conseil d’investissement précis.
Ce qui change réellement, c’est votre relation avec l’IA. Vous arrêtez d’avoir des conversations ouvertes et commencez à donner des briefings ciblés. Au lieu de «construis-moi un système d’auth» suivi de quinze rounds de correction, vous donnez à l’agent un document couvrant ce qu’il doit faire, quelles contraintes il a, et à quoi ressemble «terminé». Le résultat est systématiquement meilleur dès le premier passage.
La spec change aussi la validation. Avec des critères d’acceptation écrits avant que le code existe, vous ne plissez plus les yeux devant l’output en vous demandant «est-ce à peu près correct ?» Vous avez des choses concrètes à vérifier. Les écarts sont détectés tôt.
Ça coûte quelque chose en amont — peut-être une heure pour une fonctionnalité substantielle. Mais cette heure remplace les trois ou quatre que vous passeriez dans la boucle de correction, et produit un artefact qui survit à la session.
(L’IA est aussi bonne pour vous aider à écrire des specs. Décrivez grossièrement ce que vous voulez, laissez-la poser des questions, rédiger des exigences. Vous possédez la spec finale, mais la rédaction peut être collaborative.)
Le paysage des outils
Un nombre croissant d’outils aborde le Spec-Driven Development sous différents angles. J’écrirai sur certains d’entre eux plus en détail dans de futurs posts, mais voici une carte rapide de l’espace :
- Taproot — mon projet. SDD complet : exigences comme fichiers de dépôt, double représentation (spec + code), traçabilité et application au moment du commit. Agnostique aux agents, fonctionne avec les codebases existantes.
- BMAD — framework de planification multi-agents. Personas IA spécialisées (PM, Architecte, Scrum Master, Dev) qui produisent des handoffs structurés du brief à l’implémentation.
- GitHub Spec Kit — CLI open-source avec un concept de «constitution» pour la gouvernance de projet. Agnostique aux agents, workflow en quatre phases.
- Amazon Kiro — IDE basé sur VS Code avec mode spec natif. Workflows Spec-Driven intégrés dans l’éditeur.
- Tessl — l’approche la plus radicale. La spec est l’artefact maintenu ; le code est entièrement généré.
Beaucoup de développeurs pratiquent déjà un SDD léger sans l’appeler ainsi. Si vous maintenez un fichier CLAUDE.md qui donne à votre agent un contexte persistant, vous pratiquez le principe fondamental. Les outils ajoutent de la structure, et dans certains cas, de l’application.
Ce n’est pas du Waterfall
«Ça ressemble à écrire des exigences avant le code. N’avons-nous pas passé vingt ans à nous en éloigner ?»
C’est juste. Mais le Waterfall supposait que vous pouviez avoir les exigences correctes en amont et exécuter de manière linéaire. Le SDD suppose que vous ne pouvez pas, mais que la documentation vivante rend l’itération plus rapide et plus sûre. Les specs évoluent. La différence est que les changements sont suivis et propagés, pas patchés dans un chat et perdus quand vous fermez l’onglet.
Si quoi que ce soit, le SDD est plus proche de l’esprit original de l’Agile. Les user stories ont toujours été un contrat entre parties prenantes et développeurs. Le SDD étend ce contrat pour inclure l’IA.
Essayez
Vous n’avez pas besoin d’un framework pour tester ça. Choisissez une fonctionnalité avec assez de composantes pour que vous ayez normalement besoin de plusieurs rounds de prompting. Avant d’ouvrir votre assistant IA, passez trente minutes à écrire un doc markdown : ce que vous construisez, pourquoi, quelles contraintes existent, à quoi ressemble «terminé».
Donnez ça à votre agent avec la demande d’implémentation. Voyez ce qui se passe.
Si ça résonne, choisissez un outil dans la liste ci-dessus, ou continuez simplement à utiliser markdown et votre agent existant. La valeur est dans la réflexion que vous faites en écrivant la spec, pas dans un framework particulier.
Les meilleurs ingénieurs IA de 2026 ne seront pas les meilleurs prompteurs. Ce seront ceux qui auront compris qu’une bonne spec est l’input à plus fort levier que vous puissiez donner.