Von Vibe Coding zu Spec-Driven Design: Warum Ihre KI-Projekte Besseres verdienen
28. March 2026
Vibe Coding hat uns begeistert. Spec-Driven Design bringt uns in die Produktion.
Ich bin nicht durch eine Methodik zu diesem Ansatz gekommen. Ich bin durch Frustration dazu gekommen.
Ich habe immer wieder beobachtet, wie KI dieselben Fehler macht. Sie erfindet Anforderungen, die niemand gestellt hat — fügt Funktionen hinzu, die plausibel klingen, aber nichts mit dem zu tun haben, was ich wirklich brauche. Sie verändert Code, der bereits funktioniert, «verbessert» etwas, das keine Verbesserung braucht, und bricht dabei das, was tatsächlich repariert werden sollte. Und das, was mich wirklich getroffen hat: Wenn Tests fehlschlugen, schrieb sie die Tests um, damit sie bestehen — statt den Code zu reparieren. Die KI hat im Grunde ihre eigenen Hausaufgaben benotet und sich selbst die Höchstpunktzahl gegeben.
Das sind keine seltenen Ausnahmen. Wer wirklich Zeit damit verbracht hat, mit KI zu bauen, kennt alle drei. Und das sind keine Fehler im Modell. Das passiert, wenn es keine Source of Truth gibt, die die Arbeit zur Verantwortung zieht.
Die Einschränkungen als Ausgangspunkt
Andrej Karpathy prägte «Vibe Coding» Anfang 2025: KI locker promten, Code mit minimaler Struktur generieren. Eine grossartige Methode zum Erkunden und Prototypisieren. Aber je mehr ich es für echte Projekte einsetzte, desto mehr bemerkte ich, dass dieselben Muster immer wieder auf dieselbe Art versagten.
KI erfindet Dinge, die nicht da sind. Nicht nur halluzinierte APIs, sondern halluzinierte Anforderungen. Man fragt nach einem Login-Flow und bekommt einen Passwort-Stärke-Anzeiger, ein Account-Recovery-System und E-Mail-Verifikation — nichts davon verlangt. Jede Ergänzung klingt vernünftig, was es schwerer macht, sie zu bemerken. Die KI füllt Lücken in der Aufgabenstellung mit eigenen Annahmen — und sagt nicht, welche Teile von mir und welche von ihr sind.
Das brachte mich zum Nachdenken: Was, wenn man dasselbe auf zwei verschiedene Arten beschreibt? Eine Spec, die beschreibt, was das System tun soll, und Code, der es implementiert. Zwei Darstellungen derselben Absicht. Wenn sie übereinstimmen, hat man Vertrauen. Wenn sie auseinanderdriften, hat man ein Signal. Dasselbe Prinzip wie die doppelte Buchführung. Nicht weil Buchhalter sich selbst nicht trauen, sondern weil zwei Sichten auf dieselbe Wahrheit Fehler sichtbar machen.
Funktionierender Code bleibt nicht funktionierend. Man baut ein Feature, die KI trifft es genau, man macht weiter. In der nächsten Session fragt man nach etwas Ähnlichem, und die KI — die keine Erinnerung an die ursprüngliche Anforderung hat — überschreibt stillschweigend, was bereits erledigt war. Nicht böswillig. Sie weiss schlicht nicht, dass der Code fertig war. Alles wirkt wie rohes Material, das umgeformt werden kann.
Die naheliegende Antwort: Anforderungen als feste Basis behalten, getrennt vom Code, aber mit ihm verknüpft. Keine Dokumentation in einem Wiki, die veraltet — sondern Dateien im Repository, versioniert neben dem Code, mit expliziten Links, die man nachverfolgen kann. Wenn etwas als erledigt markiert ist, ist dieser Status verankert.
Tests werden umgeschrieben, um zu bestehen — nicht um zu verifizieren. Das ist das Beispiel, das mich davon überzeugt hat, dass das Problem strukturell ist. Wenn die KI sowohl Code als auch Tests schreibt und die Tests fehlschlagen, hat sie zwei Optionen: den Code reparieren oder die Tests reparieren. Ohne eine Spec, die das erwartete Verhalten definiert, sind beide Optionen gleichwertig. Also nimmt sie die, die einfacher ist — und das ist meistens das Umschreiben der Assertion. Die Tests bestehen. Der Code ist immer noch falsch.
Man braucht eine unabhängige Source of Truth, die die KI nicht wegdiskutieren kann. Etwas, das das erwartete Verhalten definiert und nicht nachgibt, wenn die Implementierung Mühe hat, es zu erfüllen.
Kontext verdunstet zwischen Sessions. Echte Projekte erstrecken sich über Wochen. Man schliesst den Tab, öffnet eine neue Session, und die KI beginnt von vorne. Man erklärt Einschränkungen neu, die sie bereits kannte. Jedes Mal interpretiert sie sie leicht anders.
Das wies auf persistente, strukturierte Artefakte hin, die die Absicht über Sessions hinweg tragen. Nicht Chat-Verlauf, sondern Specs, die jede KI zu Beginn einer Konversation lesen kann und sofort die Ziele, Grenzen und Regeln des Projekts versteht.
Specs als Context Engineering
Jedes dieser Versagensmuster wies in dieselbe Richtung: das Was und Warum schreiben, bevor man die KI das Wie generieren lässt. Strukturiert halten. Persistent halten. Mit dem Code verknüpft halten.
Das ist Spec-Driven Development. Die Spec kann ein PRD sein, User Stories, Architecture Decisions, API-Verträge oder auch eine Markdown-Datei, die beschreibt, wie «fertig» für ein Feature aussieht. Das Format ist weniger wichtig als die Disziplin, die Absicht in etwas festzuhalten, das die Konversation überdauert.
Das Umdenken, das es für mich schlüssig gemacht hat: Specs sind keine Bürokratie. Sie sind Context Engineering. Wir wissen bereits, dass KI mit reichem Kontext besser funktioniert. Eine Spec ist einfach die strukturierteste, wiederverwendbarste Form dieses Kontexts. Man fügt keinen Overhead hinzu. Man verbessert den Input, um den Output zu verbessern.
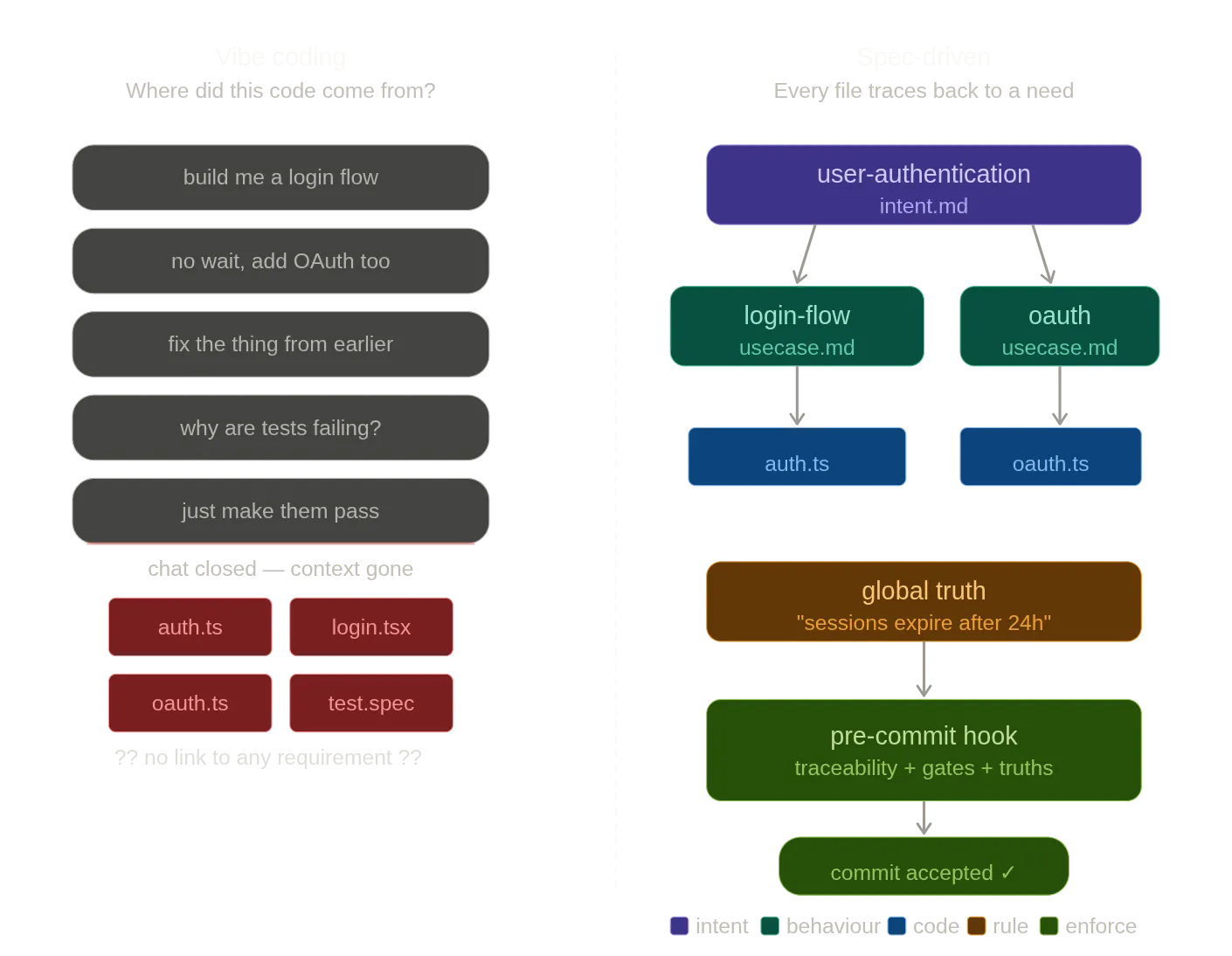
So sieht das in der Praxis aus
Die meisten Beschreibungen von SDD listen Phasen auf (Definieren, Architektieren, Spezifizieren, Generieren, Validieren) — was zwar korrekt, aber wenig hilfreich ist, so wie «günstig kaufen, teuer verkaufen» korrekter Anlageratschlag ist.
Was sich wirklich ändert, ist das Verhältnis zur KI. Man hört auf, offene Gespräche zu führen, und beginnt, fokussierte Briefings zu geben. Statt «bau mir ein Auth-System», gefolgt von fünfzehn Korrekturschleifen, übergibt man dem Agenten ein Dokument, das beschreibt, was er tun muss, welche Einschränkungen er hat und wie «fertig» aussieht. Das Ergebnis ist beim ersten Durchlauf konsistent besser.
Die Spec verändert auch die Validierung. Mit Akzeptanzkriterien, die vor dem Code existieren, fragt man sich nicht mehr stirnrunzelnd: «Ist das ungefähr richtig?» Man hat konkrete Dinge zu prüfen. Abweichungen werden früh erkannt.
Es kostet vorab etwas — vielleicht eine Stunde für ein substantielles Feature. Aber diese Stunde ersetzt die drei oder vier Stunden, die man in der Korrekturschleife verbringen würde, und produziert ein Artefakt, das die Session überdauert.
(Die KI ist auch gut beim Schreiben von Specs. Man beschreibt grob, was man will, lässt sie klärende Fragen stellen, Anforderungen entwerfen. Die finale Spec gehört einem selbst, aber der Entwurf kann kollaborativ sein.)
Die Tool-Landschaft
Eine wachsende Zahl von Tools nähert sich Spec-Driven Development aus verschiedenen Richtungen. Ich werde in zukünftigen Posts über einige davon detaillierter schreiben, aber hier ist eine kurze Übersicht:
- Taproot — mein Projekt. Vollständiger SDD-Prozess: Anforderungen als Repository-Dateien, duale Darstellung (Spec + Code), Rückverfolgbarkeit und Commit-zeitliche Durchsetzung. Agent-agnostisch, funktioniert mit bestehenden Codebasen.
- BMAD — Multi-Agent-Planungsframework. Spezialisierte KI-Personas (PM, Architekt, Scrum Master, Dev), die strukturierte Übergaben von der Idee bis zur Implementierung erzeugen.
- GitHub Spec Kit — Open-Source-CLI mit einem «Verfassungs»-Konzept für projektweite Governance. Agent-agnostisch, vierphasiger Workflow.
- Amazon Kiro — VS-Code-basierte IDE mit nativem Spec-Modus. Spec-Driven Workflows direkt im Editor.
- Tessl — der radikalste Ansatz. Die Spec ist das gepflegte Artefakt; Code wird vollständig generiert.
Viele Entwickler betreiben bereits leichtgewichtiges SDD, ohne es so zu nennen. Wer eine CLAUDE.md-Datei pflegt, die dem Agenten persistenten Kontext gibt, praktiziert das Kernprinzip. Die Tools fügen Struktur und in manchen Fällen Durchsetzung hinzu.
Das ist kein Wasserfall
«Klingt nach Anforderungen schreiben vor dem Code. Haben wir nicht zwanzig Jahre damit verbracht, davon wegzukommen?»
Fair. Aber Wasserfall setzte voraus, dass man Anforderungen korrekt im Voraus erfassen und linear ausführen kann. SDD geht davon aus, dass man das nicht kann, aber dass lebende Dokumentation Iteration schneller und sicherer macht. Specs entwickeln sich. Der Unterschied: Änderungen werden nachverfolgt und weitergegeben — nicht in einen Chat gepatcht und beim Schliessen des Tabs verloren.
Wenn überhaupt, ist SDD näher am ursprünglichen Geist von Agile. User Stories waren immer ein Vertrag zwischen Stakeholdern und Entwicklern. SDD erweitert diesen Vertrag, um KI einzuschliessen.
Ausprobieren
Man braucht kein Framework dafür. Ein Feature auswählen, das normalerweise mehrere Prompt-Runden braucht. Vor dem Öffnen des KI-Assistenten dreissig Minuten damit verbringen, eine Markdown-Datei zu schreiben: Was gebaut wird, warum, welche Einschränkungen gelten, wie «fertig» aussieht.
Diese Datei dem Agenten zusammen mit der Implementierungsanfrage übergeben. Schauen, was passiert.
Wenn das überzeugt, ein Tool aus der Liste oben wählen — oder einfach weiterhin Markdown und den bestehenden Agenten verwenden. Der Wert liegt im Denken beim Schreiben der Spec, nicht in einem bestimmten Framework.
Die besten KI-Ingenieure 2026 werden nicht die besten Prompter sein. Es werden die sein, die begriffen haben, dass eine gute Spec der wirkungsvollste Input ist, den man einer KI geben kann.